violet 感其生,历其境
初步入门嵌入式开发后(假定已经会使用Keil和CubeMX进行开发),需要回头补充的基础以及提升,本指南只起到抛砖引玉的作用,对所需知识仅作精简的概述,主要在于帮助构建知识框架
Step1 Keil+CubeMX工具链使用,HAL库使用,基本外设,基本开发常识
开发常识
该部分内容摘自队内文档部分内容
开发环境
开发环境是软件开发过程中使用的软件和硬件的组合。通常情况下包括代码编辑器、编译器、调试工具和其他工具。开发环境帮助程序员编写、测试和调试代码的环境。
IDE集成开发环境
集成开发环境是一种包含代码编辑器、编译器和调试器的综合性软件应用程序。IDE提供了方便编写、测试和调试程序的一体化界面。例如Keil,Clion,RTT Studio,CubeIDE等,本文中主要介绍Keil和Clion
代码编辑器
代码编辑器是用于编写和修改代码的工具。它提供了基本的文本编辑功能,通常还包括语法高亮、代码格式化和错误检查等特性。比如我们所使用的VScode。一般来讲,对于一个项目,代码编辑器的选择通常是无所谓的
关于单片机
单片机是一种微型计算机
单片机(Microcontroller Unit,简称MCU)是一种将微处理器、存储器(包括程序存储器和数据存储器)、输入/输出接口和其他必要的功能模块集成在单个芯片上的微型计算机。它通常用于控制应用,可以在没有外部支持芯片的情况下独立运行。
可以理解为单片机=微处理器+存储器+片上外设
- 微处理器主要负责运算与控制逻辑的执行
- 存储器用于存储代码与数据
- 外设用于实现单片机的各种功能,例如定时器的定时,输入捕获功能,USART的串口通信功能
外设
单片机外设是指用于扩展单片机功能的辅助电路,包括内部外设和外部外设,能够与单片机协同工作,实现各种控制和处理任务
例如定时器TIM和USART就是两个常见的单片机的片上外设 定时器可以用来实现定时,PWM调制,输入捕获等复杂功能 USART可以用来实现同步/异步的串口通信
关于CubeMX
CubeMX本质是代码生成器,图形化嵌入式开发辅助工具,用于快速配置STM32硬件资源并生成初始化代码框架,降低底层开发门槛,通过图形化界面,自动配置好用户所需的外设资源
CubeMX生成的代码与HAL库强绑定
关于HAL库
HAL库(Hardware Abstraction Layer,硬件抽象层)是ST公司为STM32微控制器设计的标准化硬件驱动库。作为嵌入式开发的关键基础设施,其实质是在硬件寄存器与用户应用之间构建了一个抽象接口层,彻底改变了传统嵌入式开发模式
用户只需要关注HAL库提供的抽象层,而不用去关注抽象层之下的外设寄存器操作(这类设计思想很值得借鉴)
HAL库提供统一的接口函数,例如HAL_xxxx_Transmit发送执行函数,xxxxCallback回调函数等
开发范式变为: 应用层->HAL库的抽象层->具体硬件平台
下面讨论HAL库,CMSIS协议,以及两者关系
HAL库(Hardware Abstraction Layer 硬件抽象层库)
HAL 库是 STMicroelectronics(意法半导体) 为自家 STM32 系列微控制器(MCU) 量身打造的底层软件库,是 STM32 生态中核心的开发工具之一,基于 ARM 的 CMSIS 标准构建。
CMSIS(Cortex Microcontroller Software Interface Standard)
CMSIS 是 ARM 公司 制定的 行业统一软件接口标准(注意:不是具体的软件库,而是 “规范 / 协议”),面向所有基于 ARM Cortex-M 内核(M0/M0+/M3/M4/M7 等)的微控制器,所有主流 MCU 厂商(ST、NXP、Microchip、TI、瑞萨等)均需遵循该标准。
HAL 库与 CMSIS 的关系
层级关系:CMSIS 是 底层标准,HAL 库是 基于 CMSIS 标准的具体实现——HAL 库的内核操作(如中断配置、Systick 定时器、时钟初始化)完全遵循 CMSIS-Core 规范,外设驱动接口也兼容 CMSIS-Driver 模板。
简单总结:CMSIS 是 “通用接口规则”,HAL 库是 ST 按规则为 STM32 定制的 “工具包”,两者结合既保证了跨平台兼容性,又提升了 STM32 的开发效率。
Step2 工具链的基础认知构建与工具链换新
对于整个工具链的理解,需要建立在对单片机(微型计算机)的基本工作方式有一定认知的基础上
计算机的运行都是基于机器语言,我们编写的C语言程序,最后经过编译得到汇编代码,再经过汇编,得到二进制代码(已经是机器语言,但不可运行),最后经过链接,得到一个能运行于单片机上的可执行程序
同时,还需要提一下的是,在一种计算机环境中运行的编译程序,能编译出在另外一种环境下运行的代码,这个编译过程就叫交叉编译。简单地说,就是在一个平台上生成另一个平台上的可执行代码,嵌入式开发的程序编译就是典型的交叉编译,用到的编译器用被称作交叉编译器
目前队内的开发工具链是VScode/Clion+arm-none-eabi/armclag+CMake+Ninja+Ozone+clangd/intellisence/Clion_LSP(编辑器+编译器+项目构建工具+项目构建的执行工具+烧录器+语法服务支持LSP),个人认为还是相当现代化且高度自定义的
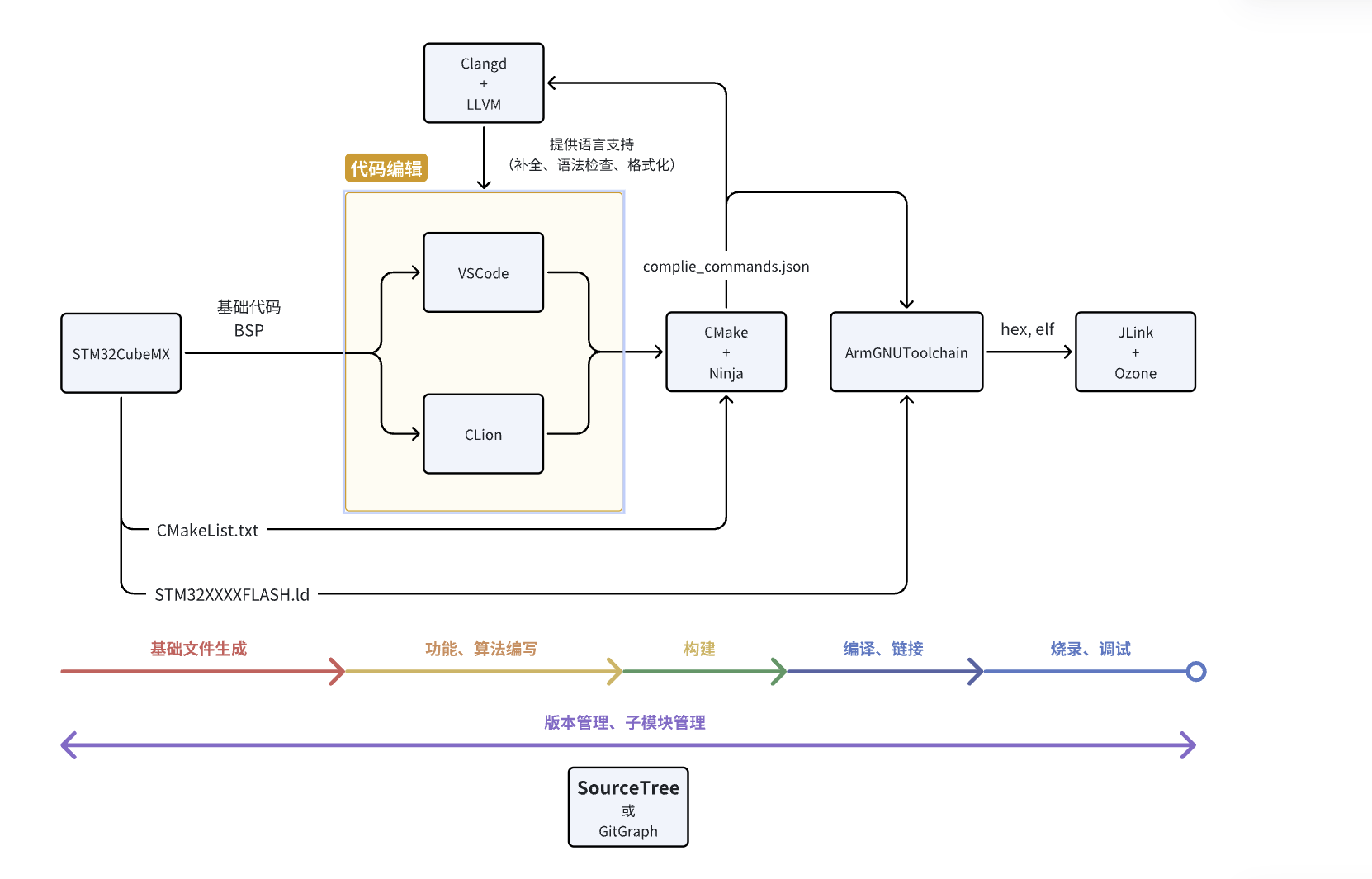
下面简单讲解C语言到机器语言的定义以及编译过程
从C语言到机器语言
机器语言
计算机(包括单片机)是不能直接识别我们所编写的C语言程序。它只能识别机器语言,而机器语言是用二进制代码表示的计算机能直接识别和执行的一种机器指指令系统令的集合
汇编语言
汇编语言是一种用于微处理器、微控制器或其他可编程器件的低级语言。 在不同的设备中,汇编语言对应着不同的机器语言指令集。 一种汇编语言专用于某种计算机系统结构,而不像许多高级语言,可以在不同系统平台之间移植。汇编语言的主体是汇编指令,汇编语言是二进制指令的文本形式,与指令是一一对应的关系。比如,有一些架构的汇编指令中的加法指令00000011写成汇编语言就是 Add
通俗的理解,汇编语言与对应计算机的架构相关,x86和arm结构的计算机分别有一套对应的汇编指令,而汇编语言是机器语言的文本化表达,例如 某一汇编指令中00000011可以简记为Add
高级语言(C&C++&Java等)到机器语言
-
高级语言到汇编语言需要经过编译,例如 .c文件经过编译后,会生成 .s文件
-
汇编语言到机器语言需要经过汇编,例如 .s文件经过汇编后,会生成 .o文件
需要注意的是,高级语言具有迁移性,在不同架构的计算机上高级语言是不变的,但是汇编语言对于不同的架构会有不同的指令,
这就需要我们选择对应的编译器,例如stm32是arm架构的芯片,在C编译器的选择上需要 选择将C语言编译为arm架构汇编语言的编译器,例如armcc,armclang,arm-none-eabi等编译器
所以在嵌入式开发中,需要根据单片机的架构选择对应的编译器
编译原理
C语言编译原理涉及将C语言代码转换为机器语言的过程。这个过程包括预处理、编译、汇编和链接。编译器在这个过程中对源代码进行优化和转换,生成可执行文件,主要包括以下几个阶段:
1. 预处理(Preprocessing)
作用:处理源代码文件中的预处理指令,如#include和#define 过程:替换宏定义,处理条件编译指令,包含头文件内容 工具:预处理器,如cpp、armclang
2.编译(Compilation)
作用:将预处理后的源代码转换成汇编语言 过程:进行语法分析和语义分析,生成汇编代码 工具:编译器,如GCC、armclang
3.汇编(Assembly)
作用:将汇编语言转换成机器语言,即目标代码(Object Code) 过程:汇编器将汇编指令转换为机器码 工具:汇编器,如as、armasm
4.链接(Linking)
作用:将多个目标代码文件和库文件合并成一个单独的可执行文件
过程: 解决外部符号引用,如函数和全局变量 合并不同模块中的相同段(如.text,.data) 生成最终的可执行文件或库文件 工具:链接器,如ld、armlink
编译器与链接器
在整个编译过程中,编译器和链接器是核心组件,一般的环境配置也主要针对这二者展开:
编译器(Compiler):负责将源代码转换成汇编代码或直接生成目标代码。编译器的高级优化包括循环优化、常数传播、死码删除等 链接器(Linker):负责将多个目标代码文件整合为一个可执行文件。链接器处理符号解析、重定位等任务
多文件编程
简单来说就是头文件提供声明(就是给编译器说有某一个函数),源文件里面有函数的具体定义/实现
多文件编译时会生成多个二进制文件,链接器会实现重定位后生成唯一的可执行文件(也就是最后实现 main.c能使用usart.c里面的函数)
核心原理:分离式编译与链接
编译链接过程
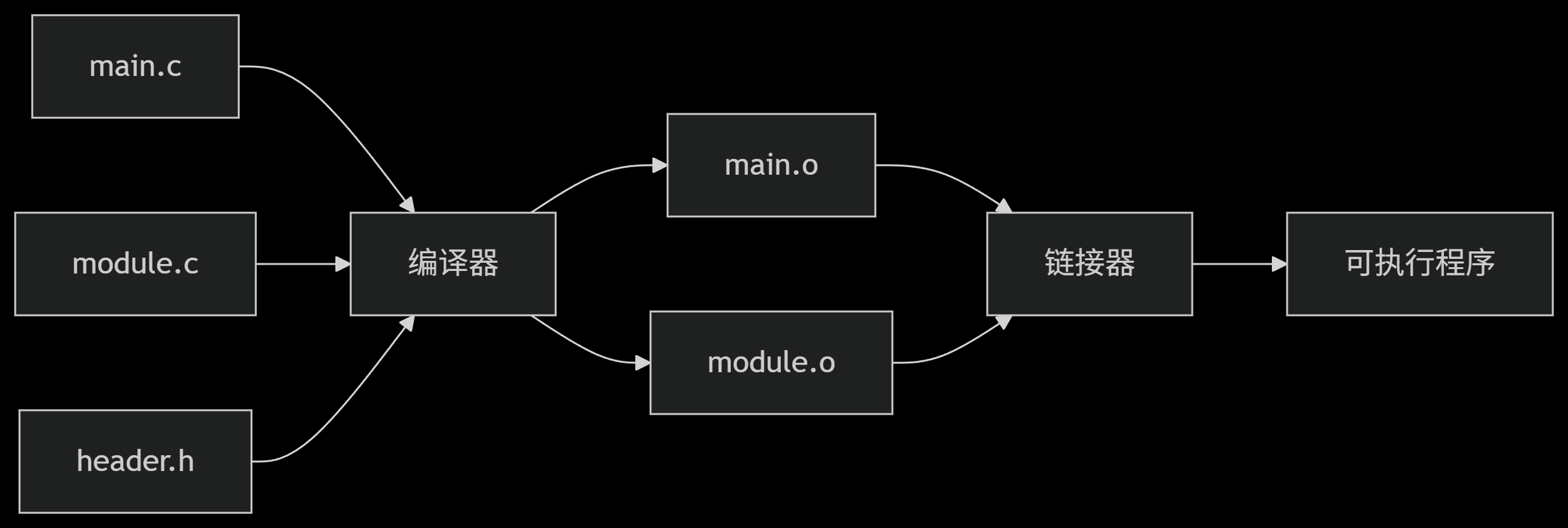 关键步骤
关键步骤
- 预处理阶段:处理
#include指令,将头文件内容复制到源文件中 - 编译阶段:将每个.c文件独立编译为目标文件(.o)
- 链接阶段:合并所有目标文件,解析符号引用,生成可执行文件
作用域与链接属性
1. 存储类说明符
| 关键字 | 文件内作用 | 文件间作用 | 典型用途 |
|---|---|---|---|
static |
私有 | 不可访问 | 内部辅助函数 |
extern |
声明 | 可访问 | 全局变量声明 |
| (默认) | 定义 | 可访问 | 公共函数 |
2. 作用域控制示例
|
|
符号解析与重定位
链接器核心任务
- 符号解析:将符号引用与符号定义关联
- 重定位:合并目标文件,调整地址引用
符号类型
| 符号类型 | 定义位置 | 引用位置 | 链接器处理 |
|---|---|---|---|
| 强符号 | .text/.data | 其他文件 | 必须唯一 |
| 弱符号 | 未初始化全局变量 | 其他文件 | 可覆盖 |
| 外部引用 | 未定义 | 当前文件 | 需在其它文件找到定义 |
符号解析示例
|
|
链接器符号表处理
- 扫描所有目标文件,收集符号定义
- 构建全局符号表:
- 强符号:记录地址
- 弱符号:标记为可选(weak关键字)
- 解析引用:
- 找到匹配的强符号
- 或使用弱符号(如果存在)
- 报告未解析引用错误
总结
在上述内容的基础上,我们可以知道,无论是Clion还是VScode,其本质都还是代码编辑器(虽然Clion内置了编译器),配环境实际上配的都还是对应的编译器(现代的编译器包含了编译器,汇编器,链接器等),如arm-none-eabi的gcc/g++或者是 arm-clang和arm-cc
Step3 C&C++混合编程,CMake&Make&Ninja
C&C++混合编程
核心原理 在于C与C++的符号修饰,如何利用extern "C"命令实现C call C++以及C++ call C
【关于C和C++混合编程中编译和链接的问题】https://www.bilibili.com/video/BV1Zm4y1E7nm?vd_source=5a0790755035f26a67935abfbfcdfd5b
extern “c"的用法:c与c++的互相调用 - 青山牧云人 - 博客园 C++–名字修饰_c++的函数名修饰是在哪个阶段进行的-CSDN博客 C/C++ 函数签名与名字修饰(符号修饰)-CSDN博客 C/C++中的 extern 和extern“C“关键字的理解和使用(对比两者的异同)_c extern c-CSDN博客
符号修饰
在C/C++中,一个程序要运行起来,需要经历以下几个阶段:预处理、编译、汇编、链接。
名字修饰(Name Mangling)是一种在编译过程中,将函数、变量的名称重新改编的机制,简单来说就是编译器为了区分各个函数,将函数通过一定算法,重新修饰为一个全局唯一的名称。
由于C++和C的名字修饰规则不同(不同操作系统下的编译器的名字修饰方式也会不同),导致C++可以支持函数重载,而C不支持函数重载
可以简单理解为,c++中支持函数重载,c语言不支持函数重载,这造成了c++和c语言的函数名解析不同(名字修饰/符号修饰)。c语言函数名就是函数名,c++的函数名是函数名+参数组合起来的。
C与C++符号修饰的实例
extern “c"的用法:c与c++的互相调用 - 青山牧云人 - 博客园 (直接copy自该博客)
比如,函数void func(double a) 在C和C++中的编译阶段函数名称会被解析成什么呢?
在C语言中,由于没有名称修饰,所以在编译时函数名称仍然是func,不会因为参数类型或数量而改变。
在C++中,由于名称修饰的存在,函数名称在编译阶段会被编译器转换成一个包含函数原型信息的唯一标识符。通常会涉及函数返回类型、参数类型以及参数数量。以GCC(GNU Compiler Collection)为例,func(double a)会被转换成_Z4funcd ,这里:
_Z:是GCC用来表示修饰名称的前缀4:表示函数名称func的的字符数d:是double类型的编码
因此,用c++的方式去寻找c语言的符号是无法寻找到的。extern "C"为何可以做到?
extern "C"的作用就是修改了符号表的生成方式,将c++符号的生成方式换成了c的生成方式。
即c库中生成的符号是c编译器的符号, 因此c语言可以直接链接。而c++程序需要使用extern "C"让编译器使用c的符号命名方式去进行链接,这样才能找到对应的符号。
extern “C”
C/C++中的 extern 和extern“C“关键字的理解和使用(对比两者的异同)_c extern c-CSDN博客
看这一篇就够了 看实例
- cpp调用c,cpp编译时会有C++的符号修饰,导致链接C库的函数找不到,需要用extern “C"告诉g++编译器以C语言的风格进行编译
- c调用cpp(不涉及C++的类和成员函数),设计一个C的接口,接口的实现在cpp中,接口函数内部去使用C++的特性
- c中调用c++成员函数,需要一个接口函数
CMake这一块
CMake是一个C/C++项目构建工具 根据CMakeLists.txt来构建makefile/ninja文件,再根据makefile/ninja文件来编译C和C++文件并生成可执行文件
只需要理解
在命令行使用g++ 进行多文件编译时,每次输入都需要输入一大堆的文件,非常麻烦
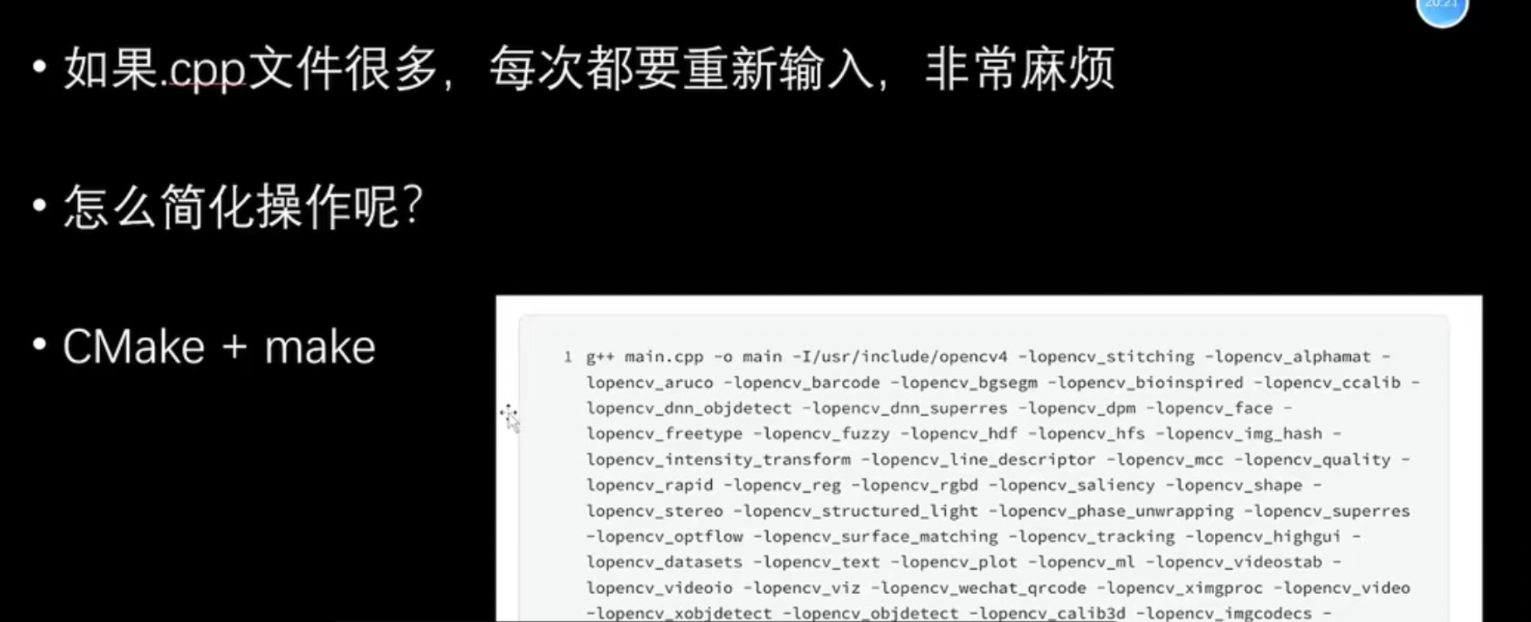 使用CMake+make/ninja进行简化操作即可(个人认为的CMake的一个核心思想(极简化理解))
使用CMake+make/ninja进行简化操作即可(个人认为的CMake的一个核心思想(极简化理解))
层级关系
- 开发者层:编写CMakeLists.txt定义构建规则
- 生成器层:CMake解析配置,生成底层构建文件
- 执行器层:Make/Ninja执行具体构建命令
- 工具链层:编译器(如gcc)、链接器等实际执行编译
cmake
cmake是一个生成 .ninja 和 .makefile 的工具。cmake只需要用户通过对源码文件的简单描述(就是CMakeLists.txt文件),就能自动生成一个project的makefile文件或者ninja文件,然后就可以通过ninja或者make进行启动编译了,很多IDE都在用cmake作为项目管理工具。
make与ninja
make功能强大,可以给人看,ninja启动速度快,项目构建速度快,但不是给人看的
可以认为两者同级。
Step4 C++提升&设计模式
这一节也是本人极其欠缺的,目前正在恶补
C++的提升推荐C&C++ 系统学习(自荐这一块儿)
设计模式推荐:暂无
C++提升
内存对齐
一文轻松理解内存对齐 - 知乎 这里仅以结构体的内存对齐为例,不提供具体例子,具体例子详见上面的博客
结构体(struct)对齐
规则 1:成员地址 = min(自身对齐值, 有效对齐值) 的倍数
规则 2:结构体总大小 = 最大成员对齐值的整数倍
规则 3:成员排列顺序影响最终大小
|
|
|
|
|
|
深拷贝与浅拷贝
1. 浅拷贝(Shallow Copy)
原理:仅复制对象的成员值(包括指针的值),不复制指针指向的实际资源。
结果:原对象和拷贝对象的指针成员指向同一块内存地址。
|
|
浅拷贝的核心问题:
- 悬空指针:一个对象释放资源后,另一个对象的指针失效
- 重复释放:多个对象尝试释放同一块内存 → 崩溃
- 数据篡改:通过一个对象修改数据会影响其他对象
2. 深拷贝(Deep Copy)
主要用于拷贝构造函数,赋值运算符
原理:不仅复制对象成员,还复制指针指向的资源。
结果:原对象和拷贝对象拥有完全独立的资源副本。
|
|
深拷贝的核心优势:
- 资源独立:每个对象拥有自己的资源副本
- 安全析构:不会发生重复释放
- 数据隔离:修改一个对象不影响其他对象
构造函数&拷贝构造函数&赋值运算符
1.构造函数
用于初始化对象的特殊成员函数,与类同名,无返回值
- 可重载,支持默认参数
- 若未显式定义,编译器生成默认构造函数
- 对象创建时自动调用
|
|
2.拷贝构造函数
用已有对象初始化新对象时调用的特殊构造函数,注意与赋值运算符区分
- 参数为同类对象的 const 引用
- 若未显式定义,编译器生成默认拷贝构造函数(浅拷贝)
- 涉及动态内存时必须显式定义(深拷贝)
|
|
需要注意的是,不用再拷贝构造函数中先判断是否删除data的动态内存,因为拷贝构造函数本质还是一个构造函数,初始化时调用
3.赋值运算符
当类中包含指针或需要深拷贝的数据成员时,使用默认的赋值运算符可能会导致问题,如内存泄漏或重复释放内存。因此,在这些情况下,需要显式地重载赋值运算符。
注意赋值运算符在内存管理上的细节
- 避免自赋值
- 赋值前先回收,避免内存泄漏
|
|
模板(函数模板&类模板)
函数模板生成的实例化成为模板函数,类模板和模板类的定义同理
函数模板
定义:通用函数定义,支持多种数据类型,编译器根据实际类型(隐式实例化)或者显式实例化生成具体函数 特点:
- 用 template 关键字声明
- 可显式或隐式实例化
- 支持函数重载和特化 模板的定义(实现),还是模板的全特化,都建议放在头文件
|
|
类模板
定义:通用类定义,成员变量和函数可使用模板参数类型。
特点:
- 类内成员函数可在类内定义(默认内联) 或类外定义
- 支持全特化和部分特化
- 实例化时需指定具体类型
|
|
现代C++相关(待补充)
自推导,lambda表达式,智能指针,RAII与RTTI的概念
设计模式
To be continued
Step5 arm-cortex-M学习&启动文件与链接器脚本
在对上面的抽象层级有一定了解后,还需要将上述偏软件的抽象层与具体的硬件相连接,建立软硬结合的认知需要有一定微机原理的知识
自荐一下笔者的博客 从CPU架构到操作系统实现
cortex-M
架构特性
Cortex-M 系列作为微控制器内核,采用哈佛架构(指令与数据独立存储但共享内存空间),具备低功耗、高性能、中断易用性强、代码密度高等优势,支持嵌入式操作系统运行。其内核演变包含 Cortex-M0/M3/M4 等多个型号,其中 M3/M4 集成 3 级流水线(取指 - 译码 - 执行),M4F 额外支持浮点运算单元
核心组件包括:
- NVIC(嵌套向量中断控制器):管理中断响应,支持多级中断优先级。
- MPU(内存保护单元):实现内存访问权限控制,保障系统安全。
- 调试接口:支持 JTAG 或 Serial Wire 调试,搭配嵌入式跟踪模块(ETM)实现代码跟踪。
- 指令集:主要支持 Thumb/Thumb2 指令集(16 位 + 32 位混合),兼顾代码密度与执行效率,属于 RISC 架构(精简指令系统),每条指令仅完成单一操作,硬件实现简单高效。
内存分布规则
重点看Flash和RAM,以及对应的段分配规则
Cortex-M 芯片内存分为 FLASH和 RAM两大区域,具体分布由硬件特性和链接脚本共同定义,以 STM32F103C8Tx(64K FLASH、20K RAM)为例:
| 内存类型 | 起始地址 | 大小 | 权限 | 存储内容 |
|---|---|---|---|---|
| FLASH | 0x8000000 | 64K | 可读可执行 | 中断向量表、.text 代码段、.rodata 只读常量段 |
| RAM | 0x20000000 | 20K | 可读可写 | .data 初始化数据段、.bss 未初始化数据段、堆、栈 |
| 内存段特性: |
- .isr_vector:位于 FLASH 起始地址,存储栈顶地址和中断 / 异常处理函数地址,是复位后内核首个访问的区域。
- .text:存放可执行代码(函数实现),包括用户代码和启动文件逻辑。
- .rodata:存储只读常量(如 const 变量、字符串字面量),节省 RAM 空间。
- .data:存放已初始化的全局 / 静态变量,编译时初始值存于 FLASH,运行时复制到 RAM。
- .bss:存放未初始化的全局 / 静态变量,运行时由启动文件清零,无需占用 FLASH 空间。
- 堆 / 栈:堆从低地址向上生长(供 malloc 使用),栈从高地址向下生长(供函数调用、局部变量使用),由链接脚本预留空间。
Flash区,起始位置0x8000000
| 段名称 | 起始地址 | 结束地址 | 内容 |
|---|---|---|---|
| .isr_vector | 0x8000 0000 | 按需计算,四字节对齐 | 中断向量表 |
| .text | 紧邻.isr_vector末尾 | 按需计算,四字节对齐 | 程序 |
| .rodata | 紧邻.text末尾 | 按需计算,四字节对齐 | 常量 |
| .ARM.extab | 紧邻.rodata末尾 | 按需计算 | ARM异常处理信息 |
| .ARM.exidx* | 紧邻.ARM.extab末尾 | 按需计算 | ARM异常索引表 |
| .preinit_array | 紧邻.ARM.exidx* 末尾 | 按需计算 | C++预初始化数组 |
| .init_array | 紧邻.preinit_array末尾 | 按需计算 | C++构造函数数组 |
| .fini_array | 紧邻.init_array末尾 | 按需计算 | C++析构函数数组 |
| .data | 紧邻.fini_array末尾 | 按需计算,四字节对齐 | 初始化变量的初始值 |
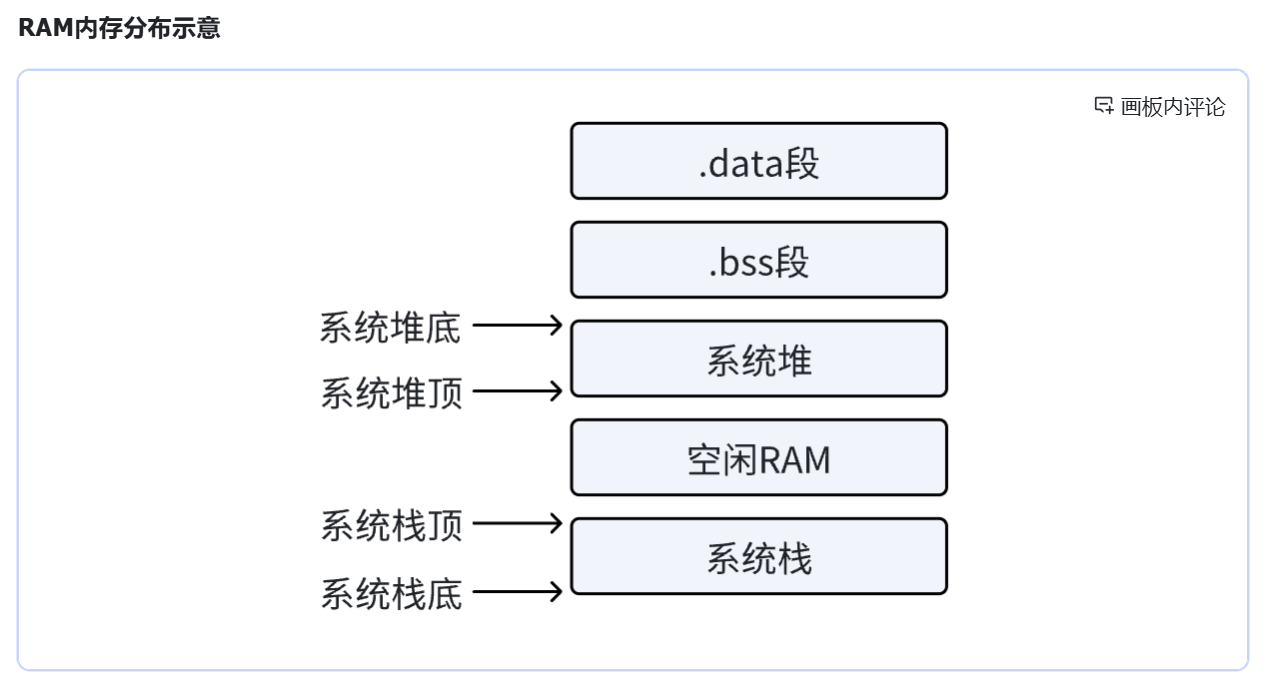
RAM区,起始位置0x20000000
| 段名称 | 起始地址 | 结束地址 | 内容 |
|---|---|---|---|
| .data | 0x2000 0000 | _edata,拷贝自Flash区 | 已初始化全局/静态变量 |
| .bss | _edata | _end | 未初始化全局/静态变量 |
| 系统堆底 | _end | _end | 堆底 |
| 系统堆栈最小预留空间 | _end | _end+预留空间 | 堆栈预留空间 |
| 空闲RAM | _end+预留空间 | _estack | 空闲空间 |
| 系统栈底 | _estack(RAM末尾) | _estack(RAM末尾) | 栈底 |
启动文件与启动原理
启动原理
- 硬件复位:内核读取 FLASH 起始地址的中断向量表,初始化 MSP(栈顶地址),将 PC 指向
Reset_Handler。 - 执行 Reset_Handler:完成时钟配置、内存段初始化(.data 复制、.bss 清零)。
- 进入用户代码:跳转至
main函数,启动流程结束,正式运行应用逻辑。 - 中断响应:运行中触发中断时,内核从向量表查找对应处理函数地址,执行后返回断点。
启动模式
STM32F103 支持 3 种启动模式,由 BOOT0 和 BOOT1 引脚电平决定:
- BOOT0=0:主 FLASH 启动(默认模式),从用户代码区启动。
- BOOT0=1、BOOT1=0:系统内存启动,从芯片出厂固化的 Bootloader 启动。
- BOOT0=1、BOOT1=1:嵌入式 SRAM 启动,从 RAM 加载代码(用于调试)。
启动文件
启动文件(如startup_stm32f103xb.s)是汇编语言编写的底层程序,作为 “硬件到软件的桥梁”,负责衔接硬件复位与用户main函数,核心功能包括硬件初始化、内存初始化、中断系统准备和引导用户代码
启动文件结构拆解
(1)汇编环境配置
指定处理器架构、指令集和浮点模式,确保汇编代码与硬件兼容,例如:
|
|
(2)关键符号声明
引用链接器脚本定义的内存地址符号,建立启动文件与内存布局的关联,例如:
|
|
(3)复位处理函数(Reset_Handler)
复位后执行的核心逻辑,是启动流程的入口,分为 5 个关键步骤:
- 系统时钟初始化:调用
SystemInit函数配置 HSE/PLL,将时钟从 8MHz HSI 提升至 72MHz - .data 段复制:从 FLASH 的
_sidata地址复制初始值到 RAM 的_sdata至_edata区域 - .bss 段清零:将 RAM 中
_sbss至_ebss区域全部置 0,符合 C 语言标准 - C++ 静态构造函数初始化:调用
__libc_init_array,执行全局对象构造(兼容 C++ 项目) - 跳转至 main 函数:完成底层初始化后,将程序控制权交给用户代码
(4)中断向量表(g_pfnVectors)
存储所有异常 / 中断的处理函数地址,位于 FLASH 起始地址,核心特性包括:
- 第 0 个元素为栈顶地址(
_estack),用于初始化主栈指针(MSP) - 第 1 个元素为
Reset_Handler地址,是复位后程序计数器(PC)的初始指向 - 向量表顺序隐含中断优先级,靠前元素对应优先级更高(如硬 fault 优先级高于 SysTick)
(5)默认中断处理函数(Default_Handler)
为未自定义的中断提供 “兜底” 逻辑,通过无限循环防止程序跑飞,同时支持弱别名机制(.weak),允许用户在 C 代码中重定义中断函数覆盖默认逻辑
链接器脚本
链接脚本(.ld)是链接器的配置文件,本质是告知链接器芯片内存布局、代码 / 数据的段分配规则、全局符号定义和内存合法性检查,是生成可执行文件(.elf/.hex)的关键,没有它链接器无法确定 “代码放哪里、变量放哪里”
(1)入口点与栈顶定义
指定程序入口和栈堆大小,例如:
|
|
(2)内存区域定义(MEMORY 块)
描述 FLASH 和 RAM 的物理属性,例如:
|
|
(3)段分配规则(SECTIONS 块)
定义编译生成的段与物理内存的映射关系,核心段包括:
- .isr_vector:分配到 FLASH 起始地址,用
KEEP关键字防止被优化删除。 - .text:存放代码段,定义
_etext标记结束地址。 - .rodata:存放只读常量,分配到 FLASH。
- .data:运行地址在 RAM,加载地址在 FLASH,定义
_sidata(加载地址)、_sdata(运行起始)、_edata(运行结束)。 - .bss:分配到 RAM,定义
_sbss(起始)、_ebss(结束)。 - ._user_heap_stack:预留堆和栈空间,检查 RAM 容量是否充足。
- /DISCARD/:丢弃无用段(如标准库冗余代码),减小文件大小。
链接脚本与启动文件的协同关系
启动文件与链接脚本通过全局符号和段分配紧密耦合,二者协作关系如下:
| 协作维度 | 启动文件角色 | 链接脚本角色 |
|---|---|---|
| 内存地址提供 | 引用_sdata、_ebss等符号 |
计算并定义内存地址符号 |
| 段分配依据 | 将代码 / 数据放入指定段(如.text) | 规定段的存储位置(如 FLASH/RAM) |
| 程序入口指定 | 实现Reset_Handler函数 |
通过ENTRY指定入口为Reset_Handler |
| 内存合法性检查 | 依赖符号确保内存访问不越界 | 检查堆 / 栈 / 数据段总大小是否超过 RAM 容量 |
- 架构→内存→链接脚本:Cortex-M 的哈佛架构决定内存分为 FLASH 和 RAM,链接脚本根据硬件内存参数(起始地址、大小)定义存储规则。
- 链接脚本→启动文件:链接脚本提供内存地址符号(如
_sdata),启动文件依赖这些符号完成.data 复制、.bss 清零等初始化操作。 - 启动文件→架构:启动文件根据 Cortex-M 内核特性(如向量表位置、栈初始化要求)实现底层逻辑,最终引导程序进入用户代码。